Model Deployment Overview
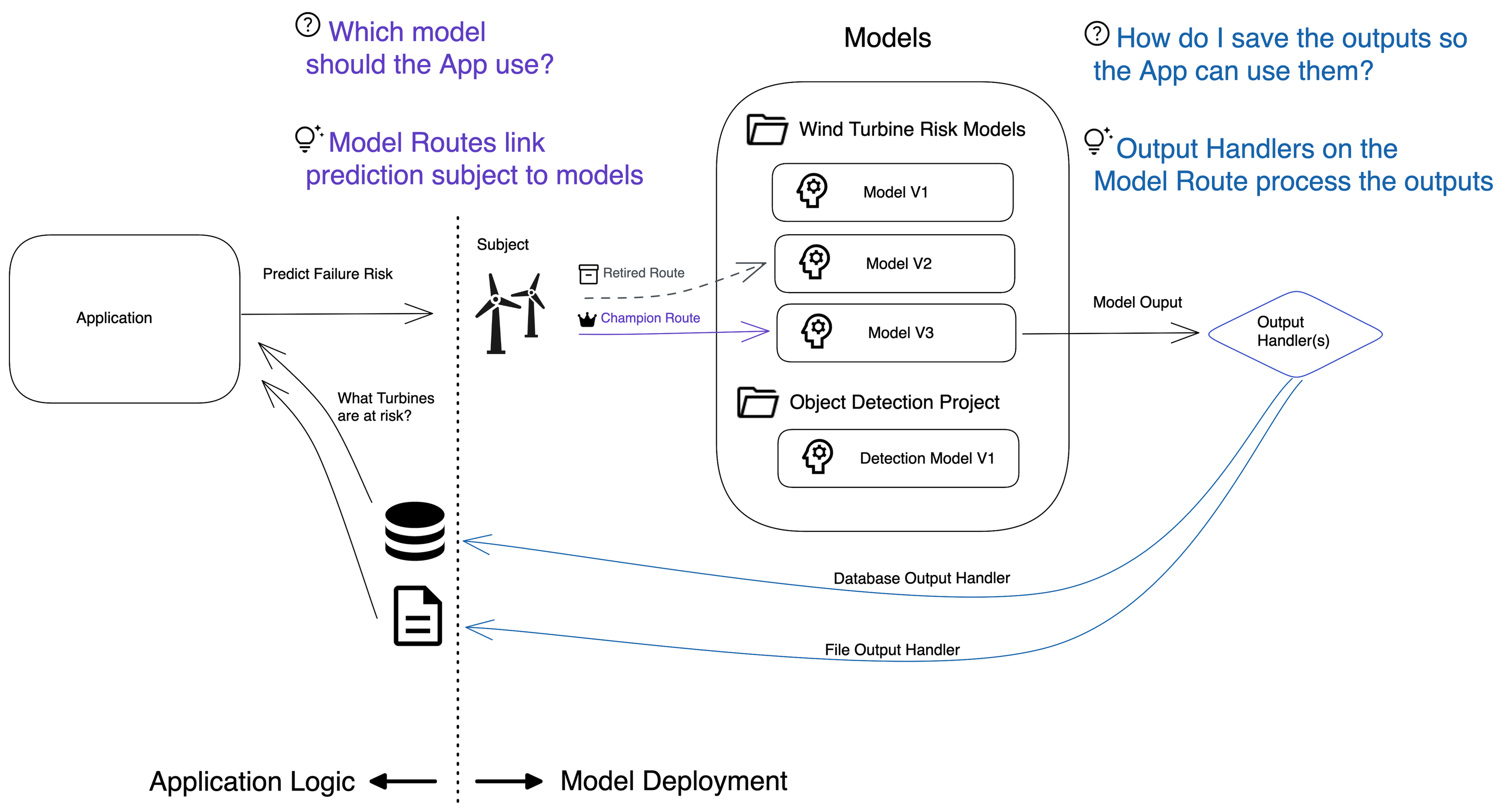
The Model Deployment Framework (MDF) helps data scientists and application developers train, deploy, and manage the life cycle of machine learning models. When a C3 AI Application requests a prediction, the MDF routes the predictions to the correct models and persists the outputs.
Model deployment enables the flexible configuration of both simple single-model deployments (for example, one model serving all predictions) and complex multi-model deployments. This enables data scientists and application developers to:
Serve models for predictions
Handle the life cycle of models, including deployment, retraining, and retiring
Route requests of predictions to the correct model
Persist predictions in a consistent way to ensure traceability back to the model
For a tutorial notebook example of using model deployment, see Tutorial Model Deployment - Predictive Maintenance for Wind Turbines.
Why use model deployment?
Model deployment separates the application logic from the model serving logic, which can save you extra effort in specifying unique application logic across models.
For example, if you're developing an application that predicts the failures of 100 wind turbines, you need to train a model for each wind turbine. This results in 100 models. Your application would need to query the risk score for each wind turbine, and request updated risk scores for each wind turbine. An application could directly call an API for each model, but the application logic would need to change each time a new model is deployed.
Model deployment solves this challenge by separating the application logic from the model serving logic. Applications can request predictions for wind turbines through a single API, and model routes the predictions to the correct model for each wind turbine. Then, the model returns predictions, so that your application can query them. With the Model Deployment Framework, you can deploy new models, retire models, and promote models without requiring any changes in application logic.
Features of model deployment
Some key features of the MDF are described in this section.
Model
A model (MlModel) is a deployable unit that wraps a machine learning pipeline (MlPipeline) with several Feature.Sets that are used to generate the inputs for that pipeline.
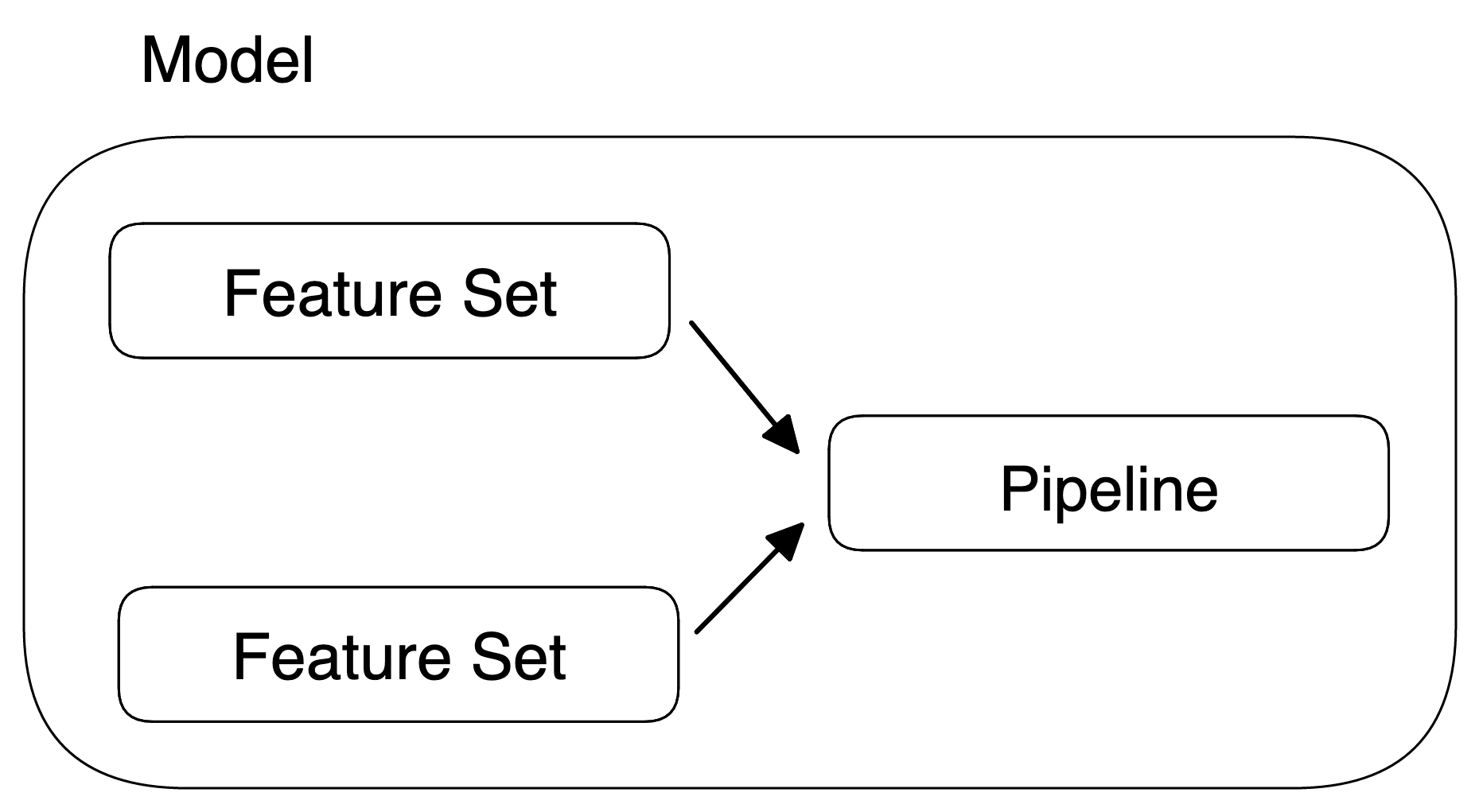
A model is immutable: The pipeline and Feature Sets cannot be changed after the model is created. This is enforced to ensure that the predictions generated by the model can be traced and audited.
Subject
A Subject (MlSubject) is an instance of a Type on which a prediction can be computed with a Model. Typically, it is an asset. Some examples can include:
- A wind turbine or a gas compressor for predictive maintenance use cases
- A financial transaction for fraud detection
- A customer in CRM applications
The subject is used to evaluate the features used by a model.
Subjects do not need to be persisted in a C3 AI data store, but they must be Identified in order to link the predictions to the correct subject.
Project
A project (MlProject) represents a business use case solved using machine learning.
Projects organize artifacts related to specific use cases, such as ML models and predictions.
Model routing
One of the core capabilities of model deployment is to pick models to compute the predictions for a given subject. This is called model routing.
Model route
A model route (MlModel.Route) represents a model deployed on a group of subjects with a specific deployment status. For example, you can Filter wind turbines by "country == 'USA'", provided the Type WindTurbine has a field country.
The route status (MlModel.Route.Status) indicates how the predictions computed by the model should be used in the application. For example, a CHAMPION model produces predictions that are used downstream in the application, whereas a CHALLENGER or CANDIDATE model is typically used to compare the performances of the models.
It is possible to customize the status with a list of tags.
Model Router
A model router (MlModel.Router) uses model routes to pick the models to use for a given subject.
The platform provides two implementations:
MlModel.RelationRouter is a router based on relations between the subjects and the models. Subjects are assigned models based on filters at the time of deployment. For more information, see MlSubjectToModelRelation.
MlModel.RuleRouter is a router based on rules that are dynamically evaluated at runtime to address use cases where storing relations is not possible or does not make sense (for example, using a single model when there are many subjects). Subjects are assigned models based on filters that are evaluated at the time of prediction.
Output Handling
At the time of deployment, MlModel.OutputHandlers are specified to convert the output and store it in a persistent location (database, file system) or forward it to an external system (for example, Kafka Queue).
C3 AI provides out-of-the-box OutputHandlers. Custom Output Handlers can be defined by
Writing to a Database using the MlModel.DbOutputHandler
Writing to a CSV using the MlModel.CsvOutputHandler
Automated recovery
Automated recovery introduces automated and manual recovery of ML Jobs including MlSubject.ProcessJob, MlSubject.InterpretJob, MlModel.Train.Job, MlModel.Route.OperationJob, MlModel.Monitor.Job, and Hpo for MlPipeline and MlModel.
For automated recovery, you can specify the maximum number of recovery attempts.