Overview of C3 AI Model Inference Service Administration
A C3 AI cluster with application(s) requiring the usage of large language models (LLMs), vision language models (VLMs), embedding models, or other large models may require a Model Inference Service to host and serve those models.
The C3 AI Model Inference Service (MIS) is a C3 Agentic AI Platform Microservice for low latency serving of machine learning (ML) models, including LLMs. With C3 AI MIS, you can host any MlAtomicPipe from the C3 AI Model Registry for a "warm" deployment and manage routing of all inference requests. See the "C3 AI MIS overview and architecture" section below for more information.
The following information is covered in this and related topics:
Overview and architecture of the C3 AI MIS - Possible architectural considerations, pre-requisites (including GPU instance sizing), and package dependencies. See below for more information.
Create and configure the C3 AI MIS - Starting the service and related services, and connecting client applications to the C3 AI MIS. See Create and Configure the C3 AI MIS for more information.
Create and deploy a
VllmPipe- Creating and registering aVllmPipeto the C3 AI Model Registry, creating an App.NodePool and deploying theVllmPipeto the specified node pool, and setting a route. See Create and Deploy a VllmPipe for more information.Manage routes of the C3 AI MIS to Change or Upgrade LLMs - Changing or upgrading models and deploying a new
VllmPipe, changing routes, and terminating outdated deployments. See Manage Routes to Change or Upgrade LLMs for more information.Monitor and scale the C3 AI MIS - Monitoring the service, and scaling up or scaling down the deployments as needed. See Monitor and Scale the C3 AI MIS for more information.
Troubleshoot and debug the C3 AI MIS and
VllmPipe- Troubleshooting tips and sanity checks, including model warmup and verifying statuses, and debugging error messages. See Troubleshoot and Debug the C3 AI MIS for more information.Make inference requests to the C3 AI MIS - Using the
c3.ModelInference.completion()andc3.ModelInference.process()APIs to call deployed models from your application. See Use C3 AI MIS for LLM Text Generation and Inference Requests for more information.
Overview and architecture of the C3 AI MIS
The C3 AI Model Inference Service (MIS) is a C3 Agentic AI Platform Microservice for low latency serving of machine learning (ML) models, including LLMs. With C3 AI MIS, you can host any MlAtomicPipe from the C3 AI Model Registry for a "warm" deployment and manage routing of all inference requests. See the "C3 AI MIS overview and architecture" section below for more information.
With C3 AI MIS, you can:
Deploy your LLMs to GPUs for highly optimized inference, including custom CUDA kernels, tensor parallelism, and continuous batching.
Deploy your MlAtomicPipes for warm inference.
Scale up and down the App.NodePools serving the models to adjust for demand.
Monitor the health of model deployments and performance with Grafana.
Call the C3 AI MIS for inference from any application with proper permissions.
Change the model serving a route without interruption to applications.
This section covers the basic architectural recommendations for setting up the C3 AI MIS, as well as the package dependencies and prerequisites. In this regard, this section also covers specific GPU instance sizing guidelines for LLM inference.
Prerequisites
Prior to completing the steps in the subsequent sections, the node pools for the cloud providers must be configured with the required resources (such as, GPUs, CPUs, memory, disk). This is typically completed by C3 AI Operations, depending on whether this is a C3 AI-managed or customer-managed deployment.
Contact your C3 AI Center of Excellence (CoE) for more information.
See also Overview of C3 AI Supported Deployments.
Considerations for GPU and RAM sizing for LLM inference
In determining the correct sizing for GPUs specifically to support LLM inference, consider the following basic guidelines:
The size of the model is approximately equal to the number of model parameters times two (2).
The GPU memory required for inference is approximately equal to two (2) times the size of the model.
GPU memory = 2 x [the size of the model], in which the size of the model is 2 x [# of model parameters]
Consider the following recommendation for allocating CPU's RAM:
RAM needs to be at least equal to the sum of the vRAM of the GPUs being used, plus 16GB for the JVM.
Example
- Model = tiiuae / falcon - 40b
- Size of model = 40 x 2 = 80 GB => This is the approximate amount of disk memory required to store the model.
- GPU memory required = 80 x 2 = 160 GB
- RAM required = 160 + 16 = 176 GB (in case vRAM of all GPUs is a 160GB).
This means that an a2-ultragpu-2g from Google Cloud might be appropriate (2 80 GB A 100s).
GPU recommendations for VllmPipe
To serve LLMs with highly optimized inference using the VllmPipe, the only supported GPUs are those with a compute capability of 7.0 or greater. See NVIDIA CUDA GPUs - Compute Capability website for more information.
Architectural design recommendations and package dependencies
There are two suggested architectures for managing the C3 AI MIS in the C3 Agentic AI Platform. While the desired architecture impacts the package dependencies, both architectures support GenAI applications. As such, the diagrams in this tutorial assume that a GenAI application is requesting LLM text generation.
The following sections describe the recommended architectures and key decision points in deciding which to use for you specific use case, as well as how these factors influence the package dependencies.
Recommended architectural designs for C3 AI MIS deployment
The recommended architectural designs differ primarily in whether the C3 AI MIS is deployed with a separate pipe registration application (Architecture 1) or as part of the same application (Architecture 2).
Architecture 1 - The Model Inference service application and the pipe registration application are separate applications
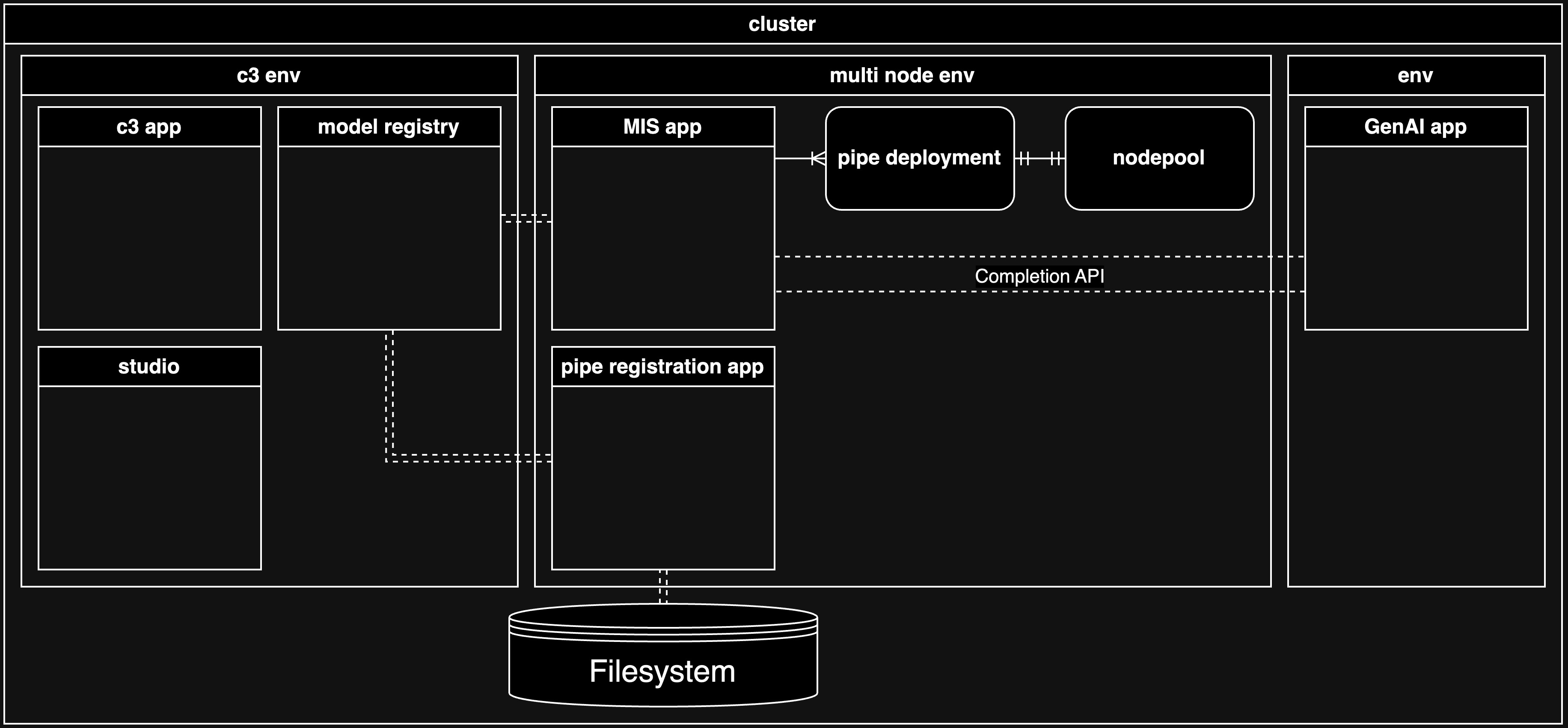
In this architecture, there is a separation of duties inherent in the design that provides security: the data scientists who are able to access the C3 AI Model Registry service and complete actions versus the administrator who is able to access the C3 AI MIS and complete actions specific to that domain.
For example, from the pipe registration application, a data scientist can create and eventually register a pipe for a large language model, which are considered data science activities. The data scientist is not able to modify the C3 AI MIS, which may be a production system delivering inference to customer applications.
From the C3 AI MIS application, an administrator is able to do several actions that you might not want the data scientist to be able to do, such as the following:
- Deploy more pipes
- Modify deployments
- Terminate deployments
- Scale deployments
Architecture 2: The Model Inference service application and the pipe registration application are the same application
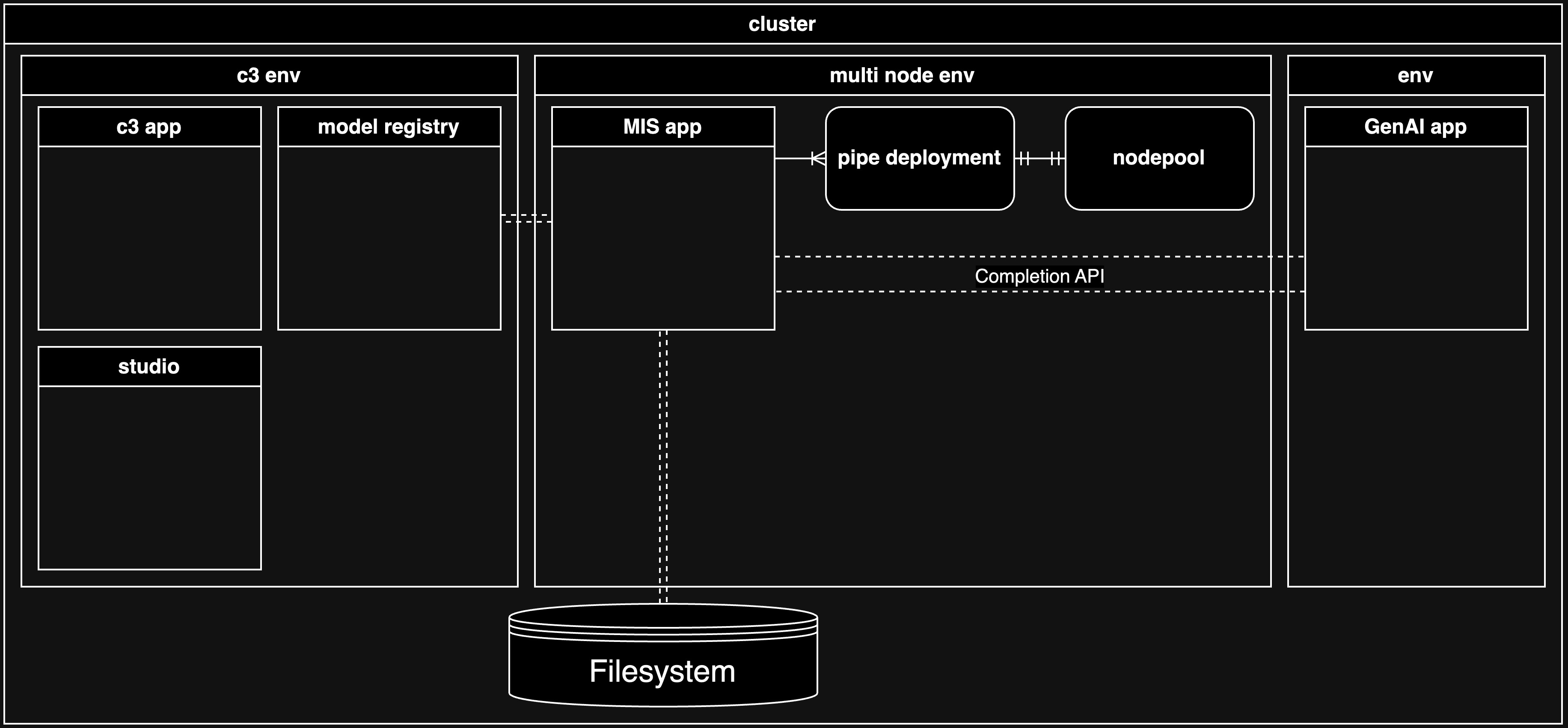
In this architecture, there is no separation of duties. The individual responsible for creating pipes also has the ability to terminate deployments, even if they are serving production applications.
Package dependencies by architectural design
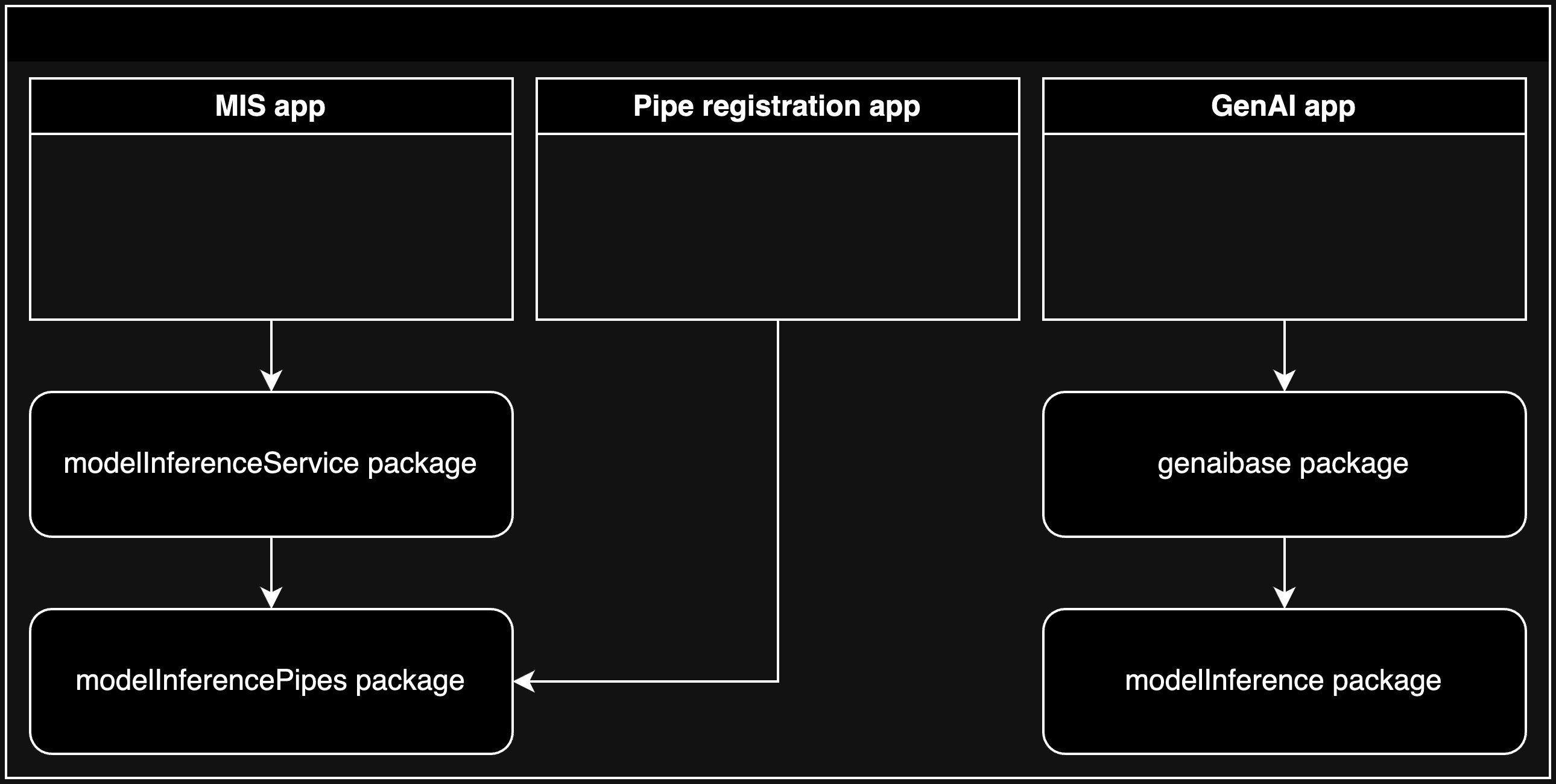
The following table includes the packages specific to the deployment of the C3 AI MIS that are considered dependencies, which depend on which architectural design you use.
| Package | Description | Repo |
|---|---|---|
modelInferenceService | Contains C3 AI MIS Types | server |
modelInferencePipes | Contains VllmPipe | server |
modelRegistryService | C3 AI Model Registry microservice Types | server |
In Architecture 1, the C3 AI MIS application depends on the modelInferenceService package, which depends on the modelInferencePipes package. The pipe registration application only depends on the modelInferencePipes package.
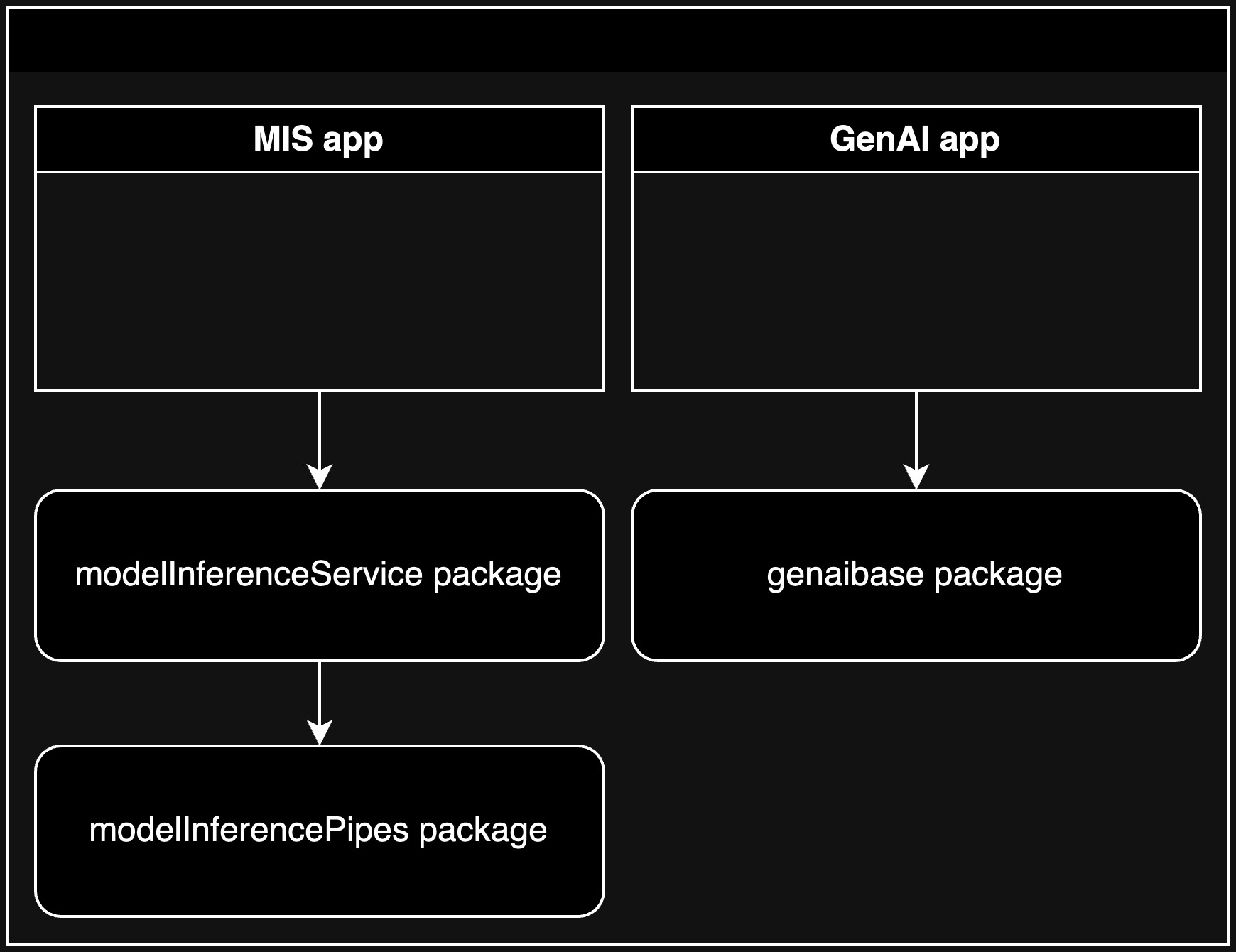
In Architecture 2, the C3 AI MIS application depends on the modelInferenceService package, and there is no pipe registration application.
| Architecture 1 | Architecture 2 |
|---|---|
 |  |