Multimodal Parsing
When you process different files, you often need to extract more than just text. Key information may appear in tables, images, or page layouts. To handle this, multimodal parsing combines layout detection with content segmentation. A layout parser first analyzes the visual structure of each page. It then uses bounding boxes to identify and separate different types of content. This approach enables accurate extraction of diverse content types and supports advanced indexing, retrieval, and search workflows.
Introduction to Mew3
Mew3 Genai.SourceFile.Chunker.Mew3 is a chunking component that supports multimodal parsing. It segments documents into structured, meaningful units using the layout structure to extract text, images, and tables. Mew3 improves the quality and consistency of parsing by integrating layout-based segmentation directly into the parsing pipeline.
By default, Mew3 uses the Docling parser to perform layout analysis. Docling is an open-source toolkit that supports various document formats, including PDF, DOCX, HTML, and images. It uses models such as DocLayNet and TableFormer to detect visual structures and identify tables. This enables Mew3 to obtain accurate bounding boxes and use them to segment content for indexing and search.
Mew3 operates as a modular pipeline. It uses producers to extract layout elements and executors to apply additional processing. This design makes Mew3 easy to configure, debug, and extend for different use cases.
Setting up Mew3
Ensure the environment and application are running with valid large language model credentials. To set the credentials, see Application Initialization.
When you run the quick start with the required model, the platform automatically enables Genai.SourceFile.Chunker.Mew3 as the default chunking component for unstructured files.
To confirm that the application is using Mew3 as the chunking component for unstructured files, run the following command in the Application C3 AI Console:
var chunkerConfig = Genai.SourceFile.Chunker.UniversalChunker.Config.forConfigKey('default');
var fileExtToChunkerSpecMap = C3.Map.fromJson(chunkerConfig.fileExtToChunkerSpecMap);
fileExtToChunkerSpecMap.get('.pdf').get('chunker');The output should display Genai.SourceFile.Chunker.Mew3, confirming that the configured chunking component is active.
If the Mew3 chunking component is not set up by default, you can follow the steps below.
Enable Mew3
Run the following in the Application C3 AI Console to enable Genai.SourceFile.Chunker.Mew3 for multimodal parsing:
Genai.QuickStart.enableMew3();This command sets Mew3 as the default chunking component for the files. It uses all default settings required for operation. The singleton Genai.SourceFile.Chunker.Mew3.Config stores the configuration for Genai.SourceFile.Chunker.Mew3.
Build Mew3 Documentation
Run the following in the Application C3 AI Console to build the documentation for the Mew3 library. This command will take a few minutes to complete.
Genai.SourceFile.Chunker.Mew3.showDocs();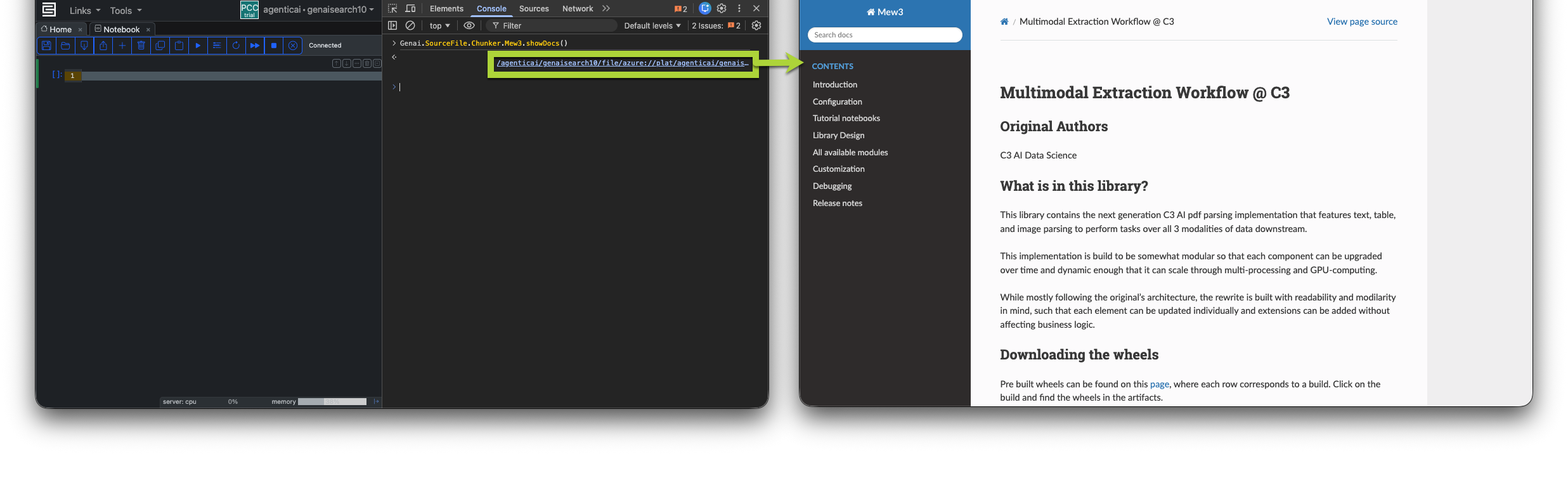
Verify configuration
var chunkerConfig = Genai.SourceFile.Chunker.UniversalChunker.Config.forConfigKey('default');
var fileExtToChunkerSpecMap = C3.Map.fromJson(chunkerConfig.fileExtToChunkerSpecMap);
fileExtToChunkerSpecMap.get('.pdf').get('chunker');The output should display Genai.SourceFile.Chunker.Mew3, confirming that the configured chunker is active.
Node Pool Configuration
Mew3 automatically uses a GPU if one is available in your cluster. Run the following command in the Application C3 AI Console to verify GPU access on a task node:
C3.app().nodePool('task').config();Review the value under the hardwareProfile.gpu field. The system sets this field to 0 when no GPU is configured on the task node.
If a GPU is not available, Mew3 automatically uses the CPU. Chunking is ~25% slower when running on a CPU, but you can increase performance by scaling the number of task nodes. For guidance on scaling task nodes and distributing chunking across nodes, refer to the Environment Sizing Guide.
Configuring Mew3
Mew3 supports more than 90 configuration options. However the default should be powerful enough for most use cases and you should only need to modify a few key settings to control model selection, update behavior, or resource usage.
Perform all configuration steps in this section using JupyterLab. To open a notebook, hover over the application card in C3 AI Studio and select Jupyter. Ensure the notebook runs with the py-mew3 runtime environment.
Access the Configuration
The following command returns the current configuration object:
c3.Genai.SourceFile.Chunker.Mew3.Config.getConfig()Most fields are empty by default because they use system-defined values unless explicitly set. The configuration remains valid and operational.
{
"type": "Genai.SourceFile.Chunker.Mew3.Config",
"pipelineSpec": {
"layout_parser_spec": {},
"text_parser_spec": {},
"image_parser_spec": {},
"table_parser_spec": {},
"text_chunker_spec": {},
"image_chunker_spec": {},
"table_chunker_spec": {},
},
"documentSpec": {},
"skipTextParsing": false,
"skipImageParsing": false,
"skipTableParsing": false
}The configuration is organized into three main areas:
pipelineSpec— Controls all parser and chunker behavior for text, images, tables, and layout.documentSpec- Specifies document processing and cropping strategiesskipParsing— Flags to enable or skip text, table, or image parsing.
The following sections describe how to update specific parameters to customize Mew3 behavior for your environment. Each parameter includes examples and expected values.
Updating pipeline specs
Before you update the pipeline spec, read the Mew3 API documentation with the Genai.SourceFile.Chunker.Mew3.showDocs() command in the C3 AI Console of your application and read the How to change your configs section on the left-hand navigation.
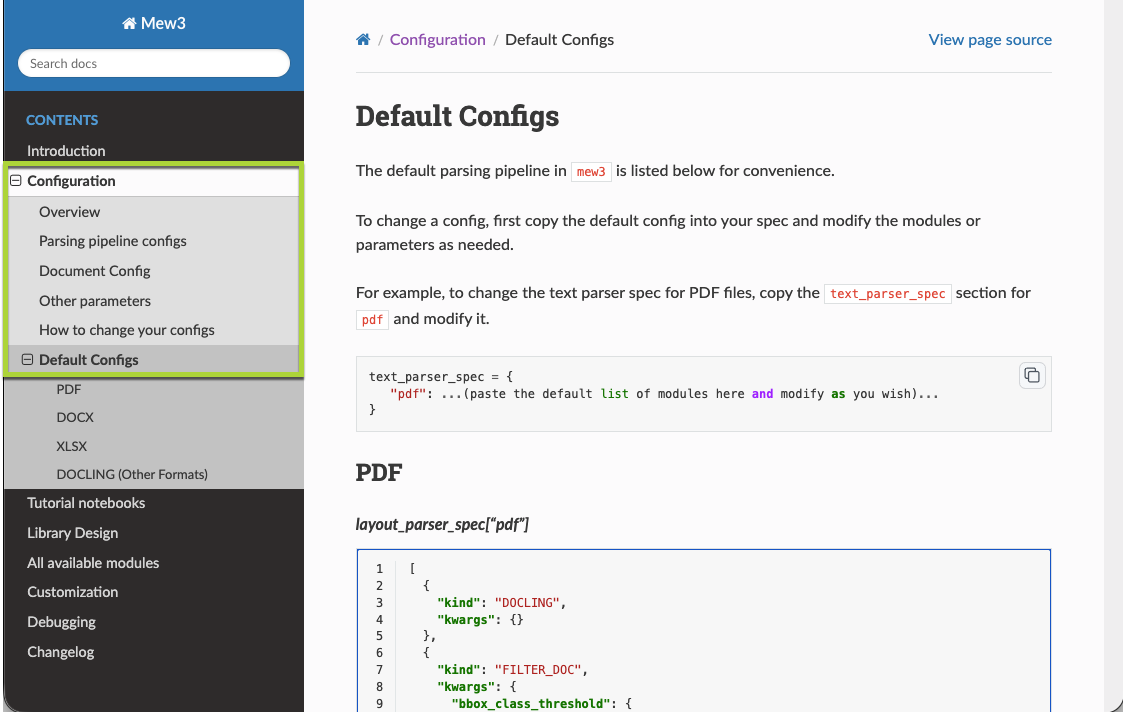
Understanding the pipeline spec structure is crucial for customizing how Mew3 processes different document types. The pipelineSpec field on Genai.SourceFile.Chunker.Mew3.Config defines the complete parsing workflow, organized hierarchically:
Pipeline Specification → Component Specification (layout parser, image parser, text parser, table parser) → File Type (pdf, docx, xlsx) → Processing Steps (modules like DOCLING, FILTER_DOC, etc.)
- Pipeline Specification
- Component Specification
- Text Parser
- Layout Parser
- Image Parser
- Table Parser
- File Type
- DOCX
- XLSX
- Processing Steps
- DOCLING
- FILTER_DOC
- ...
- Processing Steps
- File Type
- Component Specification
Each component specification maps file formats to sequential processing steps. For example, the layout parser processes PDFs through steps like "DOCLING" for structure detection, "FILTER_DOC" for confidence filtering, "UNION_BOX" for merging overlapping elements, and "ORDER_BY_COLUMN" for reading order. Processing steps can be defined as simple strings like "UNION_BOX" or as dictionaries with "kind" (module name) and "kwargs" (parameters) for complex configurations.
Layout Parser spec
This pipeline determines how the system detects and processes layout elements on each page, including headers, text, tables, lists, and their positions and uses DOCLING under the hood.
Set bounding box thresholds
Mew3 uses a confidence threshold to decide which layout elements to keep from the layout parser. These thresholds are defined in the bbox_class_threshold dictionary.
These values set the minimum prediction confidence required to keep a bounding box for each layout class. You can adjust them if you observe unwanted content removal or retention:
- Lower a value to keep more boxes of that type (for example, Picture: 0.6 → 0.4).
- Raise a value to remove noisy or low-confidence elements (for example, Page-footer: 0.2 → 0.5).
You must define and include bbox_class_threshold when you update layout_parser_spec, even if you are not changing its values.
layout_parser_spec = {
"pdf": [
{
"kind": "DOCLING",
"kwargs": {}
},
{
"kind": "FILTER_DOC",
"kwargs": {
"bbox_class_threshold": {
"Caption": 0.2,
"Footnote": 0.2,
"Formula": 0.2,
"List-item": 0.2,
"Page-footer": 0.2,
"Page-header": 0.3,
"Picture": 0.5,
"Section-header": 0.2,
"Table": 0.2,
"Text": 0.2,
"Title": 0.2
}
}
},
"FILTER_EMPTY_TEXT_BBOXES",
"UNION_BOX", # Union boxes of same class
"NO_OVERLAP", # Remove overlapping boxes of same class
"ORDER_BY_COLUMN(grid_step=150)", # Specify column spacing
"TO_MARKDOWN_CLASS", # Convert raw layout classifications to standardized markdown types
"MERGE_LIST", # Combine consecutive list items into unified list blocks
"MERGE_MANY_THINGS_BY_COLUMN", # Group related content elements within the same column layout
"RESOLVE_CLASS_CONFLICT(iou_threshold=0.85)", # merge two bbox of different class if IoU is large.
"REMOVE_CONTAINED_BOXES(containment_threshold=0.9)", # when small bboxes are contained inside one large bbox, remove the small ones if overlapping area is large.
"MERGE_TEXT_UNDER_HEADER", # For a given HEADER, merge all PLAIN below. Operates on per-pages level.
"TREAT_IMAGE_FILLED_WITH_TEXT_AS_TEXT(threshold=0.7)",
"GROW_BOX(markdown_class=['PLAIN', 'LIST', 'HEADER', 'CAPTION', 'TABLE', 'FIGURE'], rel_to='pixel', pixel_upper=2, pixel_lower=2, pixel_left=2, pixel_right=2)", # increase size of TABLE, FIGURE, or OTHER bbox
"RANGE(column='global_idx')"
]
}
Text parser spec
This pipeline parses text content such as plain text, headers, lists, and captions from the files. It filters relevant blocks and assigns structural context, including header hierarchy.
text_parser_spec = {
"pdf": [
{
"kind": "FILTER", # only keep text
"kwargs": {
"column": "markdown_class",
"include": ["HEADER", "PLAIN", "LIST", "CAPTION"],
},
},
"TEXT_EXTRACTOR.DEFAULT", # default: use cropping method
{
"kind": "GET_PARENT_HEADER_CACHED", # get parent header for text by searching for previous bboxes
"kwargs": {
"extract_header_for_type": ["PLAIN", "LIST"],
"header_parent_types": ["HEADER"],
"enable_cross_page_search": true
},
},
"TAG(column='parser', tag='TEXT')", # add 'parser' field to bbox
]
}
This setup extracts useful text from the document, including headings, paragraphs, lists, and captions. It determines the appropriate heading for each part, removes elements that are not text, and labels the result so later steps recognize it as output from a text parser.
You usually do not need to change this unless you are creating a custom setup.
Image parser spec
This pipeline detects and processes images in documents. It extracts each image, collects nearby text such as captions, and uses a language model to generate a description of the image. The image and its description are saved for further use.
image_parser_spec = {
"pdf": [
{
"kind": "GET_SURROUNDING_TEXT_CACHED", # extract text around image using adjacent bboxes
"kwargs": {
"current_bbox_typ": "FIGURE",
"extract_bbox_with_offsets": [-3, -2, -1, 1, 2, 3],
"extract_bbox_with_type": ["CAPTION", "PLAIN", "HEADER", "LIST"],
"enable_cross_page_search": false
}
},
{
"kind": "CAPTION_FINDER.LOCALITY_CACHED", # search for caption in adjacent bboxes
"kwargs": {
"current_bbox_typ": ["FIGURE"],
"search_bbox_with_offsets": [-1, 1, -2, 2, -3, 3], # represents the relative index to search for caption in sequence. Elements at front have higher priorities.
"target_bbox_type": "CAPTION",
"bbox_types_to_search_for": ["CAPTION", "PLAIN", "HEADER"],
"enable_cross_page_search": false
}
},
{
"kind": "GET_PARENT_HEADER_CACHED", # extract parent header information for context
"kwargs": {
"extract_header_for_type": ["FIGURE"],
"header_parent_types": ["HEADER"],
"enable_cross_page_search": true
}
},
{
"kind": "FILTER", # only keep FIGURE
"kwargs": {
"column": "markdown_class",
"include": ["FIGURE"]
}
},
"IMAGE_EXTRACT",
"IMAGE_VERBAL.OPENAI", # disable verbalization: "IMAGE_VERBAL.NULL"
"SAVE_IMAGE_C3", # save image to FileSystem
{
"kind": "TAG", # add 'parser' field to bbox
"kwargs": {
"column": "parser",
"tag": "IMAGE"
}
}
]
}
Table parser spec
This pipeline finds tables in documents, extracts their content, and uses a language model to summarize the contents of each table. It also captures surrounding text to provide context for each table and saves the output as both an image and a CSV file.
table_parser_spec = {
"pdf": [
{
"kind": "GET_SURROUNDING_TEXT_CACHED", # extract text around table using adjacent bboxes
"kwargs": {
"current_bbox_typ": "TABLE",
"extract_bbox_with_offsets": [-3, -2, -1, 1, 2, 3],
"extract_bbox_with_type": ["CAPTION", "PLAIN", "HEADER", "LIST"],
"enable_cross_page_search": false
}
},
{
"kind": "CAPTION_FINDER.LOCALITY_CACHED", # search for caption in adjacent bboxes
"kwargs": {
"current_bbox_typ": ["TABLE"],
"search_bbox_with_offsets": [-1, 1, -2, 2, -3, 3], # represents the relative index to search for caption in sequence. Elements at front have higher priorities.
"target_bbox_type": "HEADER",
"bbox_types_to_search_for": ["HEADER", "CAPTION", "PLAIN"],
"enable_cross_page_search": false
}
},
{
"kind": "GET_PARENT_HEADER_CACHED", # extract parent header information for context
"kwargs": {
"extract_header_for_type": ["TABLE"],
"header_parent_types": ["HEADER"],
"enable_cross_page_search": true
}
},
"RENAME(source='caption', target='title')", # rename field on bbox
{
"kind": "FILTER", # only keep TABLE
"kwargs": {
"column": "markdown_class",
"include": ["TABLE"]
}
},
"TABLE_IMAGE_EXTRACT", # crop image from page
"CSV_EXTRACT.OPENAI(output_col='csv', grounded_col='none')", # extract csv using OpenAI
"TABLE_VERBAL.OPENAI", # non-LLM options: "TABLE_VERBAL.TITLE_AND_CONTENT", "TABLE_VERBAL.NULL"
"SAVE_TABLE_IMAGE_C3", # save table image to FileSystem
"SAVE_CSV_C3", # save csv to FileSystem
"TAG(column='parser', tag='TABLE')" # add 'parser' field to bbox
]
}
Text chunker spec
Splits long text blocks into smaller chunks so they can be indexed, searched, or used by language models more effectively.
text_chunker_spec = {
"pdf": [
{
"kind": "LONG_CHAIN", # splits long text into overlapping chunks
"kwargs": {
"column_to_chunk": "text",
"split_overlap": 200 # overlap between consecutive chunks in characters
}
}
]
}split_overlap— Controls character overlap between chunks. Higher values (like 200) provide more context continuity but increase duplication. Lower values reduce duplication but may lose context at chunk boundaries.
Table chunker spec
Splits the LLM-generated description of a table into smaller chunks. This helps improve retrieval performance and allows language models to process long table summaries more efficiently.
table_chunker_spec = {
"pdf":[
{
"kind": "LONG_CHAIN", # splits table verbalization into overlapping chunks
"kwargs": {
"column_to_chunk": "verbalization",
"split_overlap": 200, # overlap between consecutive chunks in characters
"split_length": 1000 # maximum chunk size in characters
}
}
]
}split_length— Set to 1000 characters to create larger chunks for table descriptions. Increase this to produce fewer, longer chunks for better performance, or decrease for more granular search precision.split_overlap— Set to 200 characters for good context continuity between chunks. Decrease this to reduce content duplication and save storage space.
Update pipeline configurations
To configure Mew3, always follow this sequence:
- Copy the configuration block for the section you want to change (for example,
text_parser_spec,image_parser_spec,table_parser_spec, orlayout_parser_spec). - Edit only the parameters you want to change.
- When applying changes, always pass all updated specs together using
setConfigValue(). Each update must include every previously customized spec to avoid losing earlier changes. This ensures the configuration stays consistent and prevents accidental resets. - After updating, restart the chunker engines to apply the new configuration.
- You may need to restart your kernel for changes to be returned as modified.
Step 1: Copy the parser specs to your notebook
Copy the parser spec blocks you want to change from the sections below into your Jupyter notebook.
text_parser_spec = {
# (Insert your custom text_parser pipeline here)
}Step 2: Edit only the values you want to change
Modify parameters in the copied specs as needed for your environment or use case.
Go to the How to change your configs section in the left-hand side bar under Configurations for a detailed explanation of how to change specific mew3 configurations. For each spec, you must specify the file format keys first. A file format maps to a list of dictionaries, where each dictionary represents a processing step. During parsing, this list of steps is run sequentially. Those steps are modules. Select All available modules in the left-hand sidebar for the corresponding module to specify.
Step 3: Apply all changes together
Apply your changes by passing all updated specs at once to setConfigValue().
c3.Genai.SourceFile.Chunker.Mew3.Config.inst().setConfigValue(
'pipelineSpec',
{
"text_parser_spec": text_parser_spec
}
)Always include all specs you have changed. Omitting a section resets it to its default configuration.
Step 4: Add new or updated specs in future updates
When you update another spec later (for example, layout_parser_spec), include all previous changes in the same call:
c3.Genai.SourceFile.Chunker.Mew3.Config.inst().setConfigValue(
'pipelineSpec',
{
"text_parser_spec": table_parser_spec,
"image_parser_spec": image_parser_spec,
"layout_parser_spec": layout_parser_spec
}
)This method ensures the configuration remains consistent and avoids accidental resets.
Step 5: Restart the chunker engine to apply the new configuration
c3.Genai.SourceFile.Chunker.Engine.terminateAllEngines()Updating what content Mew3 parses
Mew3 supports selective parsing of text, tables, and images. By default, it processes all content types. To skip specific types, update the following configuration fields:
"skipImageParsing": false,
"skipTableParsing": false,
"skipTextParsing": falseSet a field to true to skip that content type:
skipImageParsing: Skips image extraction.skipTableParsing: Skips table parsing.skipTextParsing: Skips text extraction.
For example, to extract only tables and images:
"skipTextParsing": true,
"skipTableParsing": false,
"skipImageParsing": falseAdjust these settings to reduce processing time or focus on specific content types that are more relevant for your use case.
Steps to update
Update these settings in your Jupyter notebook as follows:
Copy and edit the relevant parameters for your use case.
Apply each change using the
setConfigValue()method.Pythonc3.Genai.SourceFile.Chunker.Mew3.Config.inst().setConfigValue('skipTextParsing', True) c3.Genai.SourceFile.Chunker.Mew3.Config.inst().setConfigValue('skipTableParsing', False) c3.Genai.SourceFile.Chunker.Mew3.Config.inst().setConfigValue('skipImageParsing', False)Restart the chunker engine to apply the new configuration:
Pythonc3.Genai.SourceFile.Chunker.Engine.terminateAllEngines()