XGBoost Classification
Categorize data using an XGBoost classification model in Visual Notebooks. XGBoost is a popular and highly efficient algorithm.
Configuration
| Field | Description |
|---|---|
| Name | Name of the node A user-specified node name displayed in the workspace, both on the node and in the dataframe as a tab. |
| Select Column with Labels | The column the XGBoost classifier should predict Select a column from the dropdown menu. This column contains the labels that the model should be able to predict after the training. |
Select Features
| Field | Description |
|---|---|
| Select Features | Features to train the model with Use all columns as features, or select specific columns using the dropdown menu. Columns selected as features are used to train the model. |
| Select optional timeseries column | Timeseries column If there is a timeseries column in your data, check the box in this field and select the timeseries column from the dropdown menu. Timeseries information is used when splitting the data into separate train, validation, and test datasets. |
Test and Validation Settings
When training models, data is split into multiple components. The bulk of the data is used for training and validation, while a small portion is set aside for testing. The fields in this section determine what percentage of the data is used for training, how the data is used during the training process, and the strategy used to split the data.
| Field | Description |
|---|---|
| Select test and validation method | Test and train method Select Train-validation-split to split the dataset into separate train, validation, and test datasets. Select Cross-validation to split the data into a specified number of subsets. During training, one subgroup is used for testing and validation, while the other subgroups are used for training. The process is then repeated so each subgroup is used as the testing and validation group once. |
| Select percentage split | Data split percentage Move the slider to split the data into test, validation, and train datasets. If Cross-validation is selected in the Select test and validation method field, move the slider to split the data into a train dataset that will be divided into subgroups, and a separate testing dataset. The default split when using the cross-validation method is 80% train and 20% test. |
| Select number of cross-validation folds | Number of cross-validation subgroups Enter a number between 2 and 20. The data allocated for training is divided into the specified number of subgroups. |
| Select sampling method | Data splitting strategy Select Stratified to ensure that each dataset and subgroup contains the same percentage of each label as the entire dataset. Select Random to randomly split the data into the percentages specified above. Note that selecting Random may result in test data that doesn't accurately represent the entire dataset. |
Scorer and Stopping Conditions
By default, Visual Notebooks trains many models with different hyperparameter configurations, then ranks the models by performance. The fields in this section tell Visual Notebooks when to stop making new models. You can stop making models once the new models no longer substantially improve upon the existing models. Alternatively, you can stop making new models after a specified number of models have been trained or a certain amount of time has passed.
| Field | Description |
|---|---|
| The performance metric | The performance metric used to stop hyperparameter search Select Logloss, AuROC, AuPR, MSE, or RMSE. When training multiple models with different hyperparameter combinations, stop creating models when the new models fail to improve a specified performance metric. This field is used in conjunction with the following two fields. |
| Does not improve by more than | The specific threshold used to stop hyperparameter search Select 0.1%, 0.01%, 0.001%, or 0.0001%. When training multiple models with different hyperparameter combinations, stop creating models when the new models fail to improve the specified performance metric by the given percentage. This field is used in conjunction with the fields directly above and below. |
| After the following number of consecutive training rounds | The criteria used to stop hyperparameter search Select a number between 2 and 10. When training multiple models with different hyperparameter combinations, stop creating models when the new models fail to improve the specified performance metric after the following number of consecutive training rounds. This field is used in conjunction with the two fields above. |
| A maximum # of models have been trialed | How many models to train Select 3, 5, 10, 20, 50, 100, 200, or 500. When training multiple models with different hyperparameter combinations, stop creating new models after a specified number of models are created. |
| A specified amount of training time passes | When to stop training new models Select 5 minutes, 10 minutes, 20 minutes, 30 minutes, 1 hour, 2 hours, 12 hours, or 24 hours. When training multiple models with different hyperparameter combinations, stop creating new models after a specified amount of time passes. |
Hyperparameters Search
As mentioned in the previous section, Visual Notebooks trains many different models with various hyperparameter combinations. The fields in this section determine the hyperparameter options used during training. Although you don't need to alter these fields to train a high-performing model, it is possible to explore different combinations.
Hyperparameters give you precise control over a model. You can use these to tell the model how quickly to learn, when to stop improving, and what to prioritize during the learning process. In general, the goal of changing the hyperparameters is to make the best possible model while avoiding overfitting. If a model is too closely aligned to the training data, it may be incapable of producing accurate predictions on unseen data.
| Field | Description |
|---|---|
| Hyperparameters Search | Train one model or multiple models Select Search to train multiple models with different hyperparameter combinations and then compare the models to find the best one. Select Fixed to train a single model with a fixed hyperparameter configuration. |
| Number of trees / estimators | The number of trees to build Enter an integer between 2 and 10,000. More trees create a more accurate model, but can lead to overfitting. Values between 50 and 200 are common. If you define a fixed model, the default is 50. |
| Maximum tree depth | The maximum number of levels in each tree Enter an integer between 1 and 100. Increasing the tree depth allows the model to fine-tune its performance, but may lead to overfitting. Values between 3 to 12 are common. If you define a fixed model, the default is 6. |
| Minimum child weight | How many data points are in a leaf node Enter an integer greater than or equal to 0. Increasing this value makes the model more generic, as it tells the model to stop splitting the tree if it will result in fewer than the specified number of data points in a leaf node. Values between 1 to 10 are common. If you define a fixed model, the default is 1. |
| Minimum split improvement (gamma) | Amount of improvement required to make an additional split of the tree Enter an integer greater than or equal to 0. Increasing this value makes the model more generic, as it tells the tree to stop splitting if it will result in an improvement less than the value of this field. Values of 0, 1, 5, and 10 are common. If you define a fixed model, the default is 0. |
| Column sample rate per tree | Amount of columns used during training by each tree Enter a number between 0 and 1. Each tree uses the given ratio of columns when training. Decreasing this value helps prevent individual columns from over-influencing the prediction. Values from 0.3 to 0.8 are common if the dataset has many columns, while values of 0.8 to 1 are common if the dataset has few columns. If you define a fixed model, the default is 1. |
| Row sample rate per tree | Amount of rows used during training by each tree Enter a number between 0 and 1. Each tree uses the given ratio of data when training. Decreasing this value helps prevent overfitting to accommodate outliers. Values from 0.8 to 1 are common. If you define a fixed model, the default is 1. |
| Learning rate | The learning speed Enter a number between 0 and 1. Decreasing this value improves performance, but increases training time. Values between 0.01 and 0.3 are common. If you define a fixed model, the default is 0.3. |
| L1 regularization (alpha) | Lasso regularization Enter a number greater than or equal to 0. Increasing this value discourages overfitting by penalizing overly complex models and removing some features. Values of 0, 1, 5, and 10 are common. If you define a fixed model, the default is 0. |
| L2 regularization (lambda) | Ridge regularization Enter a number greater than or equal to 0. Increasing this value discourages overfitting by penalizing overly complex models and lowering the importance of some features. Values of 0.01, 0.1, 1, and 10 are common. If you define a fixed model, the default is 1. |
Repeatability Seed
Random numbers are used throughout the training process for splitting the original dataset, splitting individual trees, and optimizing hyperparameters. Ex Machina uses one number, called a seed, to generate those random numbers. The field in this section allows you to enter a custom seed. If you enter a custom seed, you can enter that same custom seed at a later date to reproduce the results of the training.
| Field | Description |
|---|---|
| Seed | The number used throughout the AutoML process Select Random to use a random number, or select Custom to enter a specific integer. The seed is used to generate numbers used throughout the AutoML process. If you enter a custom seed, you can enter the same custom seed at a later date to get the same results. |
Imbalanced Data Strategy
Classification models expect data to be somewhat balanced. If one label in your dataset is severely underrepresented, models might ignore that label during training and always predict a more prevalent label. Since the minority label represents such a small portion of the data, models can use this strategy without generating a significant amount of false predictions. To prevent this behavior, Visual Notebooks balances the data by oversampling the minority label so all labels are evenly represented.
| Field | Description |
|---|---|
| Handle imbalanced dataset | Rebalance option Check this field to automatically balance the data so all labels are evenly represented. Leave the field unchecked to keep the input data unchanged. |
| Scale position weight | Prevalence of the majority class This field appears if the Handle imbalanced dataset field is checked. If your label only has two label classes, set the scale position weight to reflect the percentage of the majority label in the dataset. For example, if your dataset has 500 instances of safe transactions and 10 instances of fraudulent transactions, set the scale position weight to 98 to reflect that the majority label occurs 98% of the time. |
Prediction
The output of this node is each model's predictions on the training data. This section determines how the predictions are portrayed in the resulting dataframe.
| Field | Description |
|---|---|
| modelId | Selected model's name This auto-populated field displays the selected model's name. |
| Prediction Column Name | The column name for the model's predictions Enter a name for the column that contains the selected model's predictions. Column names can contain alphanumeric characters and underscores, but cannot contain spaces. |
| Add column with probabilistic output scores | Model prediction probabilities Leave this switch on to create a column with the model's confidence in each prediction. Toggle this switch off to create a dataframe without this column. |
| Dataset Selection | Data used to display a model's predictions Select all data, train dataset, validation dataset, or test dataset. Visual Notebooks displays a selected model's predictions on the dataset selected with this field. |
Node Inputs/Outputs
| Input | A Visual Notebooks dataframe |
|---|---|
| Output | A dataframe with predictions on the training data |
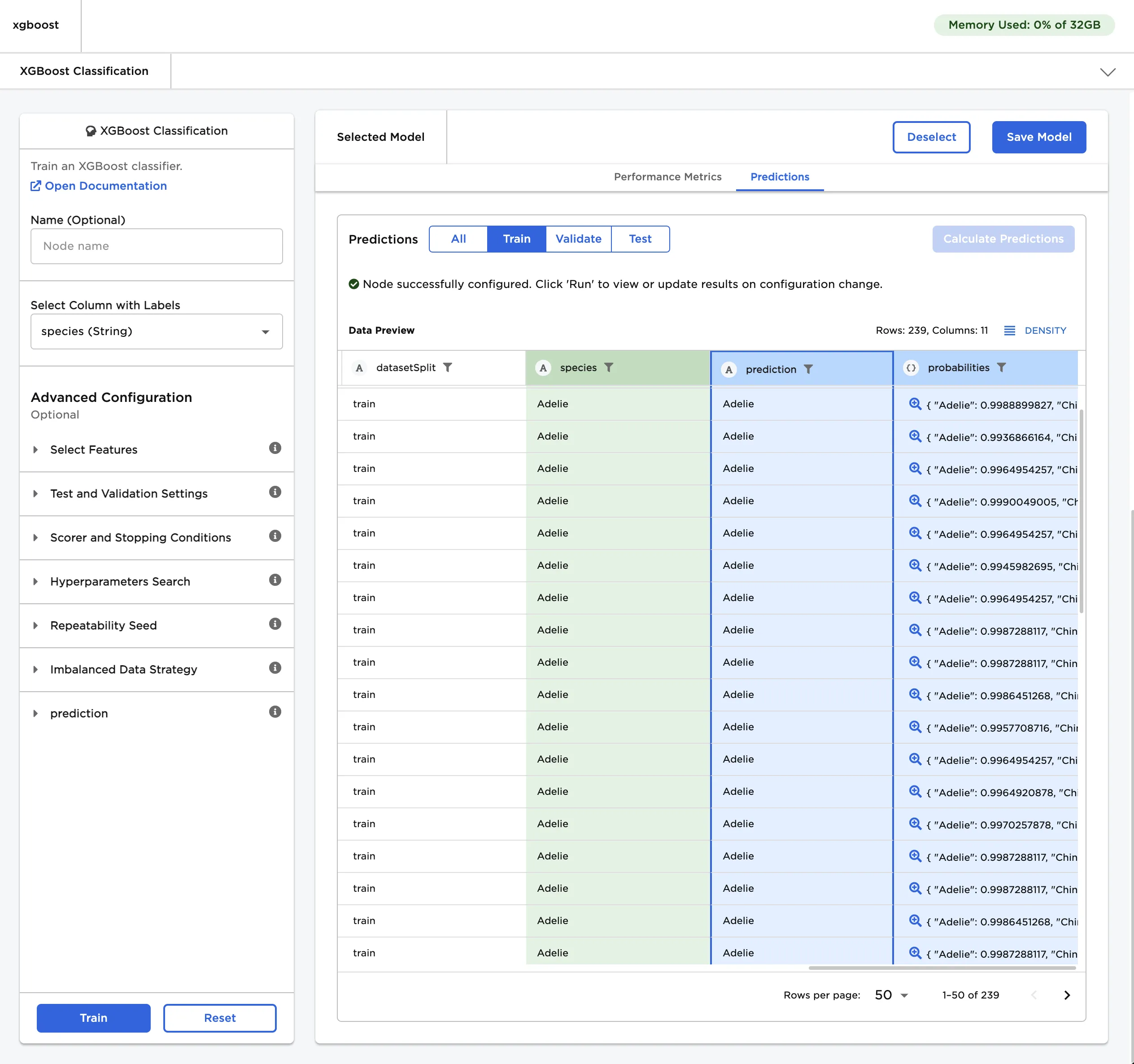
Figure 1: Example output
Examples
The dataframe shown in Figure 2 is used in this example. It contains identifying characteristics of three species of penguin. This data is used to train a model that can identify the species of penguin based on the given data.
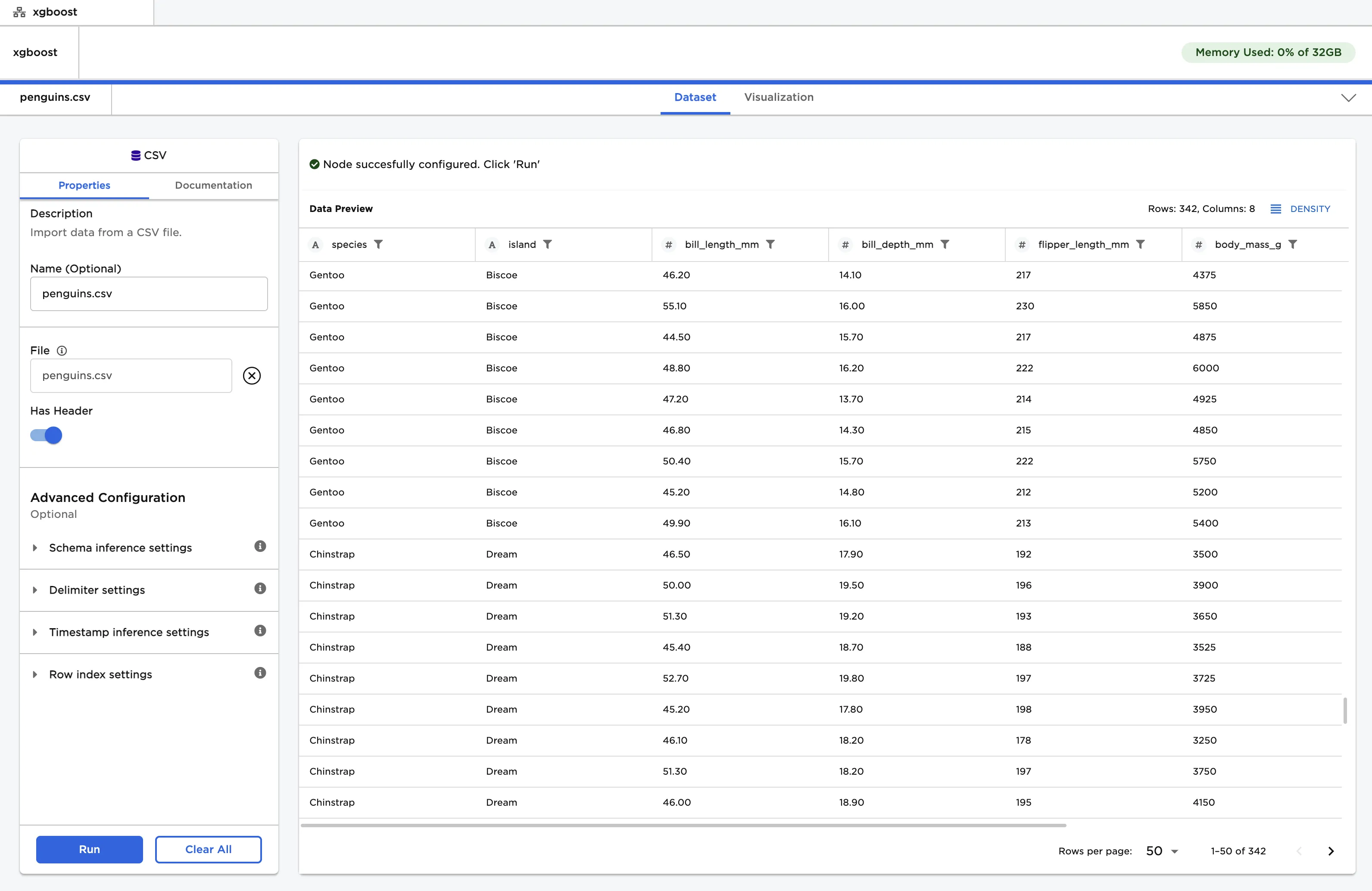
Figure 2: Example input data
- Connect an XGBoost Classification node to an existing node.
- Select species (String) for the Select Column with Labels field. The model should be able to predict the values in this column after training.
- Select Train to train models with the default settings.
Notice that Visual Notebooks trains multiple models, each with different hyperparameter configurations. All trained models are displayed on a leaderboard and ranked by performance.
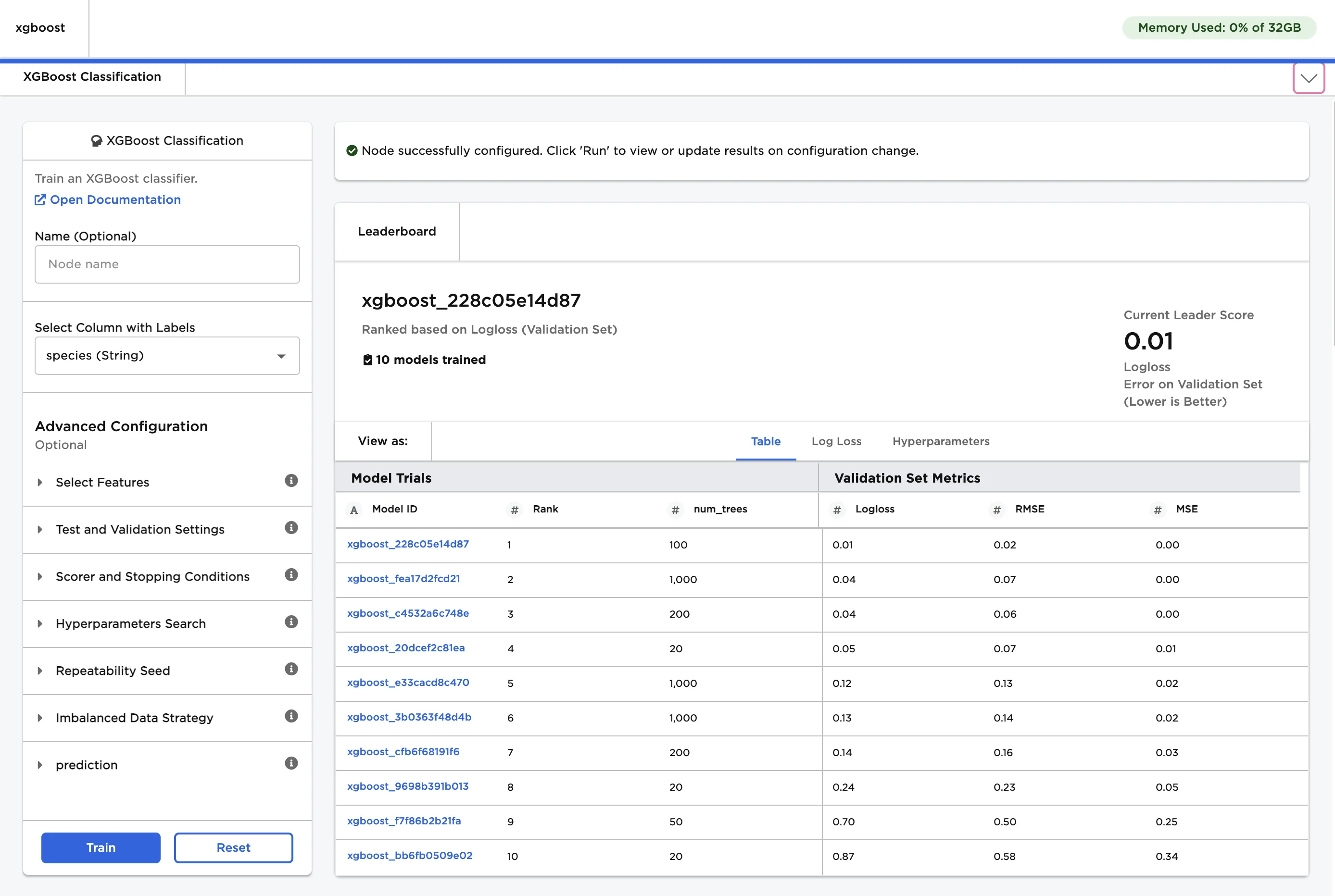
Figure 3: Model leaderboard
- Select a model, then scroll down to view information about the model and a bar chart with the importance of each feature.
- Select Calculate Additional Details to view additional test metrics and a confusion matrix. The button appears dimmed after it has been selected. For more information about test metrics, see the Visual Notebooks User Guide.
The model selected in Figure 4 determined that bill length is the most important characteristic when categorizing penguins by species.
The confusion matrix shows that the selected model correctly identifies all Chinstrap and Gentoo penguins in the data, but only correctly identifies 95.8% of the Adelie penguins. It mistakenly categorizes 4.2% of Adelie penguins as Gentoo penguins. A confusion matrix with a diagonal row of "100%" values from the top left to the bottom right indicates a perfect model.
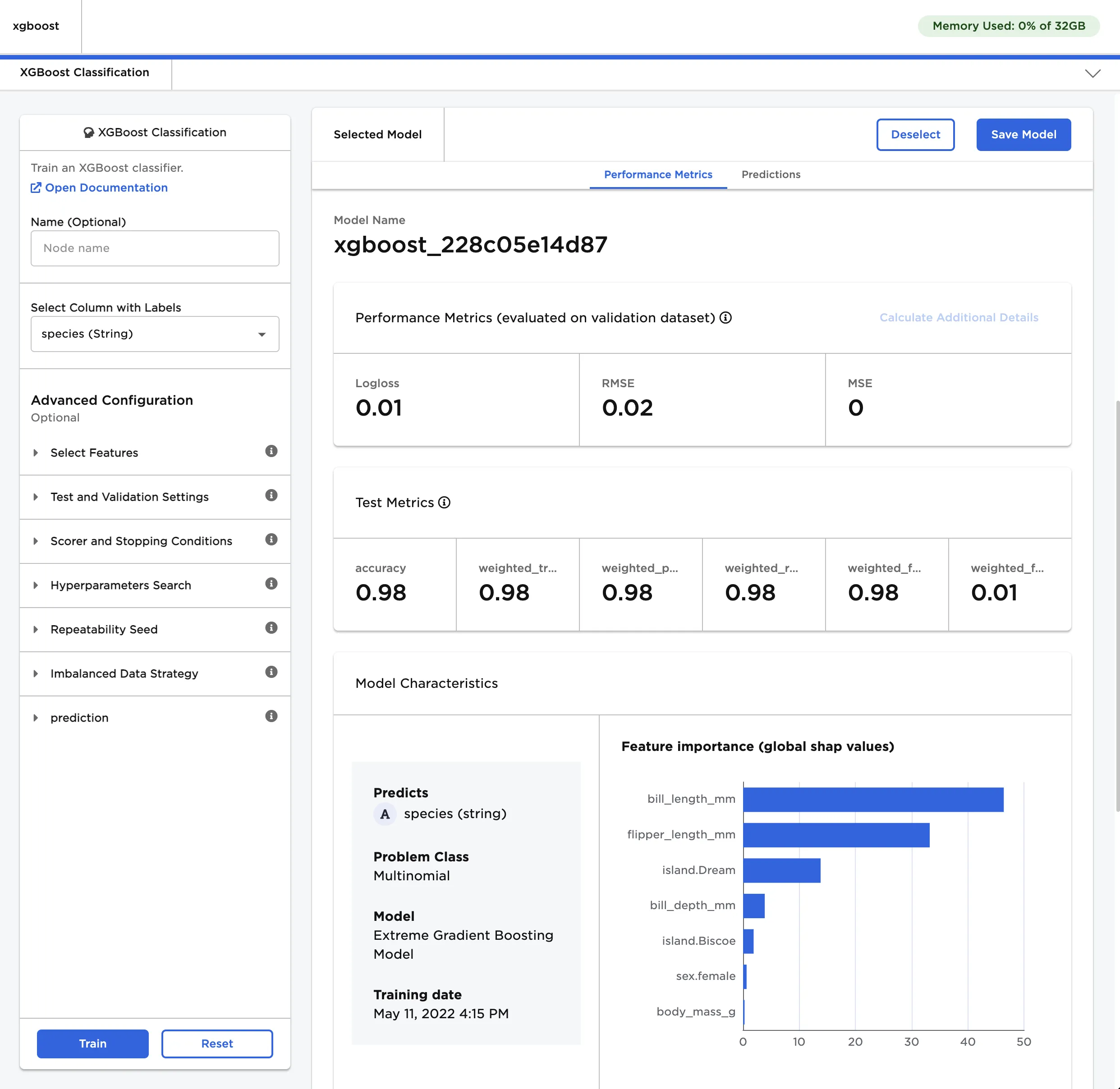
Figure 4: Model details
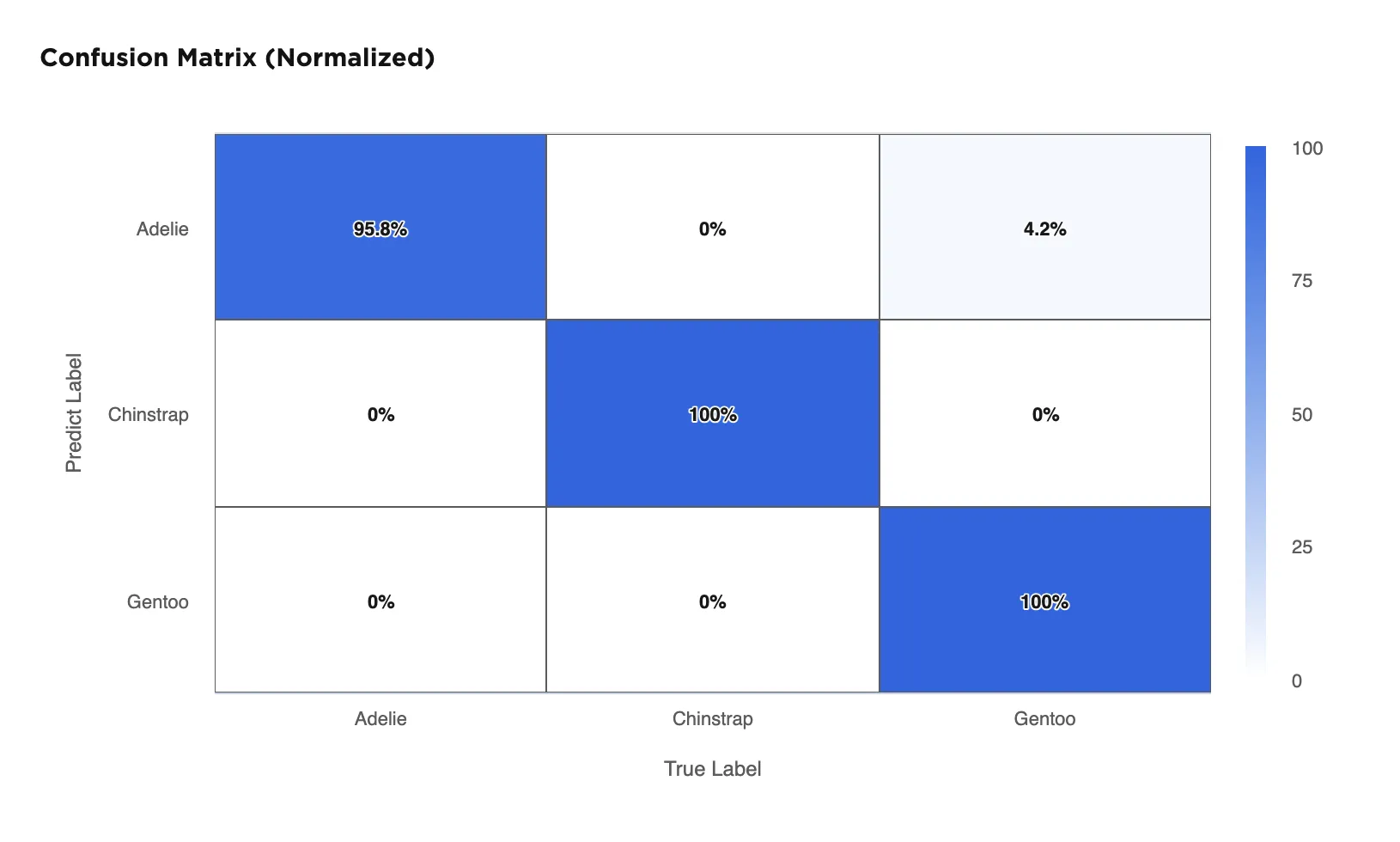
Figure 5: Confusion matrix
- After a model is selected, navigate to the Predictions tab.
- Select Calculate Predictions to view the selected model's predictions on the training data. The button appears dimmed after it has been selected.
If the leading model doesn't perform as well as you'd like it to, try altering the advanced configuration options and training new models.
Note that if your model correctly predicts all values, it might be overfit. In other words, the model may be too closely aligned to the training data that it is incapable of making accurate predictions on unseen data. Try altering the hyperparameters or using a different AutoML node.
Figure 6: The selected model's predictions